Recently I was asked again if I know a method, or even better a tool, which makes GPX points more align to the existing streets in OpenStreetMap. E.g. currently in Mapillary all recorded streets are not really smooth and digitalized if you look at them in detail. GraphHopper cannot do this out of the box but provides a toolchain which will make this digitalization easier.
Update: this is now open source.
Map Matching
The necessary process before an import would be Map Matching. Quoting (my own words ;)) from Wikipedia:
Map matching is the process of associating a sorted list of user or vehicle positions to the road network on a digital map. The main purposes are to track vehicles, analyze traffic flow and finding the start point of the driving directions.
Or as a picture:

I’m explaining in this blog post the simple steps which can taken to implement something like this with a very simple method. This is not an invention by me, other papers suggesting a similar technique. Also we should use some open testing data additionally to the normal unit tests. Some wordings are necessary before we go deeper:
- A GPS point is a tuple or object which contains latitude, longitude (, elevation) at which position it was recorded.
- A GPX point is a tuple or object which contains latitude, longitude (, elevation) and the timestamp at which it was recorded. And a GPX list ist a list of GPX points.
- In the digital world of maps we need a data structure to handle the road network. This data structure is a graph where the junctions from real world are nodes and the streets between them are the edges.
The question is also why would we need a routing engine at all?
Because:
- firstly you don’t need to write the import process of OpenStreetMap and the closest edge lookup and probably some other tools necessary for map matching and
- secondly the routing process will fill gaps between larger distances of two GPX points, and will be able to guess those gaps depending on the vehicle and
- thirdly using a routing engine will make the outcome more realistic, e.g. avoiding going left and then returning the identical street to go further in the straight direction.
- Lastly with GraphHopper you’ll be easily able to provide such a procedure even for the world wide case as it stores everything very compact and can be used in-memory or on-disc.
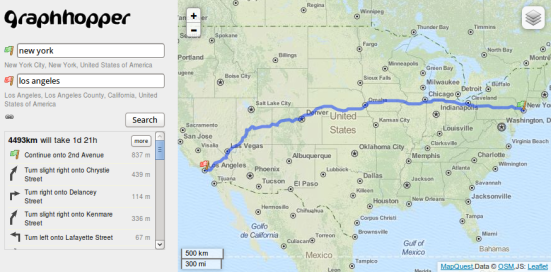
We start with an example: 
All maps are from Lyrk and data is from OpenStreetMap contributors
In the left map you see the street parts highlighted where only the edges closest to the GPX points are selected. Whereas in the right map the most probable way was taken via a routing engine like GraphHopper.
The simple algorithm
The results for the map on the left side are easy to get, see the gist for example 1. For the map on the right side can try the following procedure explained in pseudocode here or see example 2 as gist for a more complete one:
- Find 3 closest edges per GPX point
- Associate every edge with a weighting, which is the distance from the edge to the point. The larger the distance the smaller is the probability that the best path goes through it.
- Find the best path from the first GPX point to the last, but take into account the weighting and therefor the distance to the GPX points
- As a post-processing step you need to assign the GPX points to the resulting path, you can do so via the edge ids and to find the coordinates you can either use path.calcPoints or the lower level API ala edgeState.fetchWayGeometry.
This simple algorithm should work in the most cases and is very fast
The enhancements
There are two limitations of this simple algorithm:
- If there are loops in the GPX list, then the Dijkstra from step 3 will throw data away
- and it will happen that another route than the route marked with GPX points is taken. E.g. in the case if the GPX signal is not that frequent and the edge of one point is rather short, which means it will have a small influence on the overall weighting of the taken route.
The following improvements are possible
- You could do a simple workaround and cut the incoming GPX list when you detect a loop and feed those GPX-list-parts to the algorithm.
- Or find the best route not from start to end but ‘step by step’. For example from pointX to pointX+4, then pointX+4 to pointX+8 and so on, where you need to merge the results. To avoid suboptimal paths at the intersection (here pointX+4) you’ll need to ‘overlap’ the routes. So you will need to calculate the routes for pointX to pointX+4, then pointX+3 to pointX+7, …. instead. Merging will be more complex probably.
- A more complex solution could be to maintain a list of e.g. 3 alternative end-results. As you already get 3 edge candidates for every GPX point you can then try to find all routes between them. You could think that this will slow down the search a lot but with GraphHopper you can tweak e.g. the Dijkstra or DijkstraOneToMany algorithm to do this in an efficient manner. E.g. if you want to get the best result but you want to search from multiple destinations you can do: DijkstraBidirectionRef dijkstra = new DijkstraBidirectionRef(hopper.getGraph(), flagEncoder, weighting); dijkstra.initFrom(nodeFrom, distanceToPossibility1); dijkstra.initFrom(node, distanceToPossibility2); … dijkstra.initTo(nodeTo, distanceToEndPossibility1); dijkstra.initTo(nodeTo, distanceToEndPossibility2); …
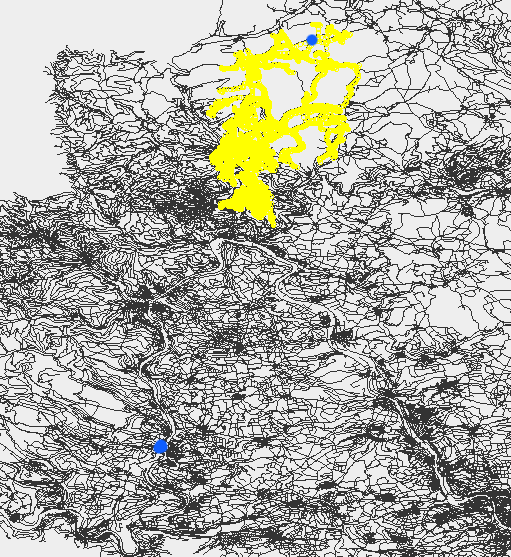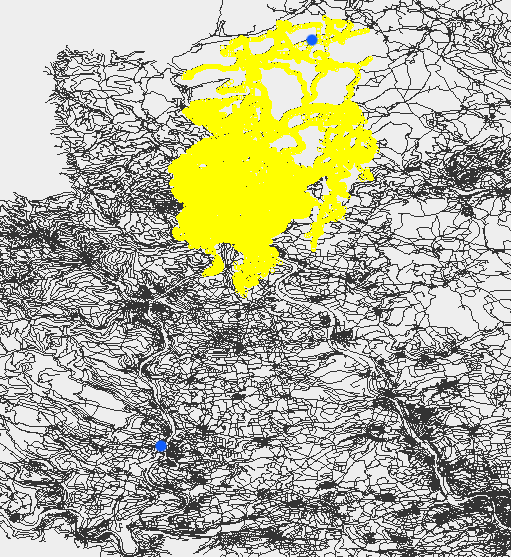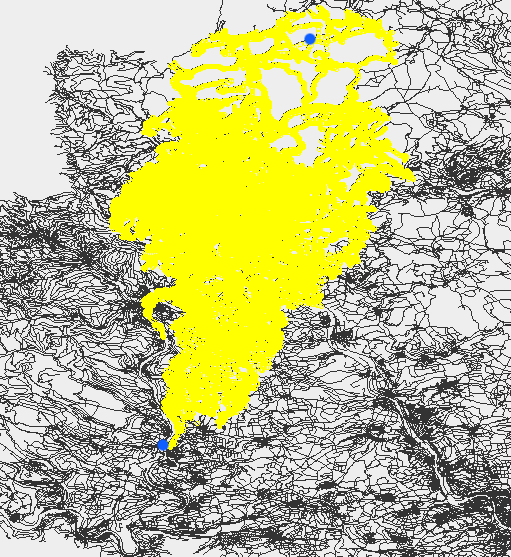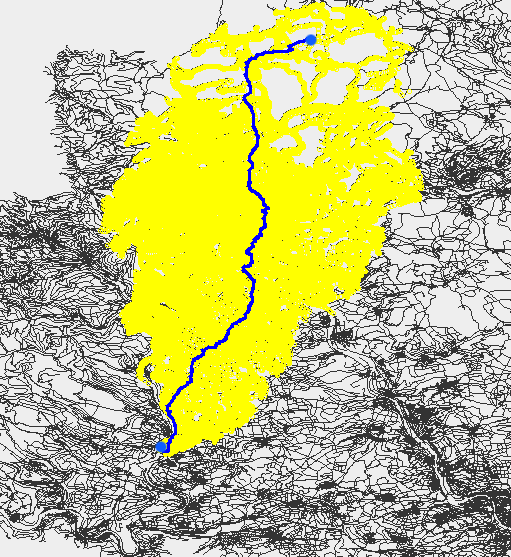
There are lots of other problems which you’ll encounter, that is the ugly real life with GPS signal errors, tunnels and so on. One example problem is if you are tracking e.g. a truck waiting in front of traffic lights in a one way street. You’ll see several nearly identical GPX points but as they have an error associated they won’t be identical and it could happen that they go ‘backwards’ in the one-way which will result in an extra loop if use the ‘step-by-step’ variant of the shortest path calculation:







{kind=link}
{kind=link}